Rapidly Realizing PracticalApplications of Cutting-edge Technologies
2023.12.11
Engineering
MN-Core runtime – software which runs MN-Core
By : Akira Kawata
2023.11.22
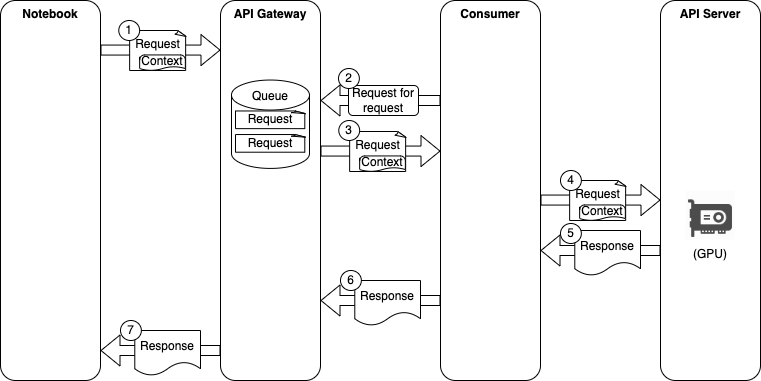
meta-fuse-csi-plugin: A CSI plugin for All FUSE implementations
By : Yuichiro Ueno
2023.11.20
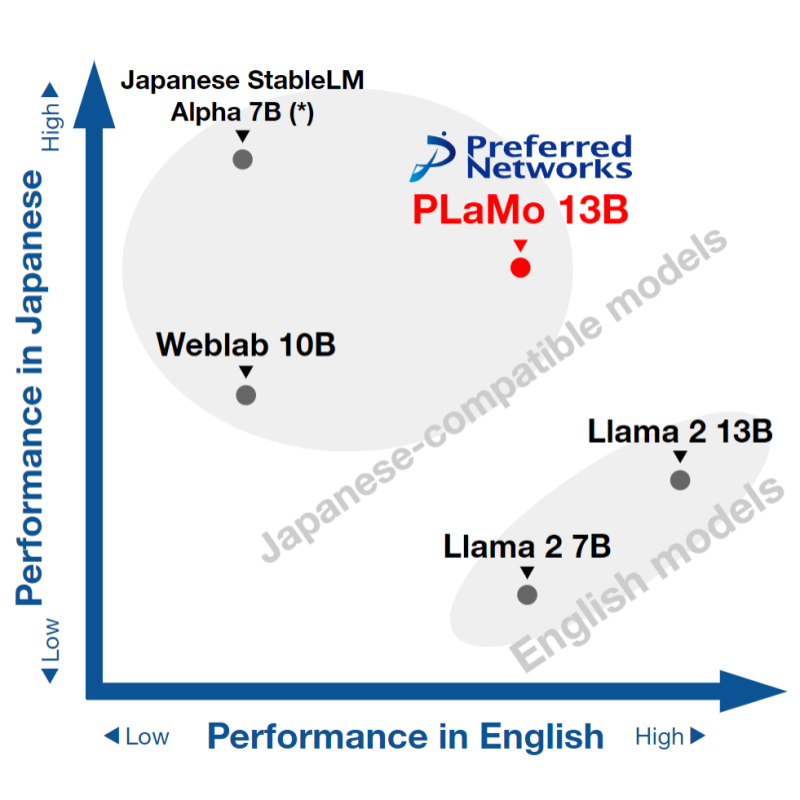
We Released PLaMo-13B
By : Hiroaki Mikami
2023.10.13
Research
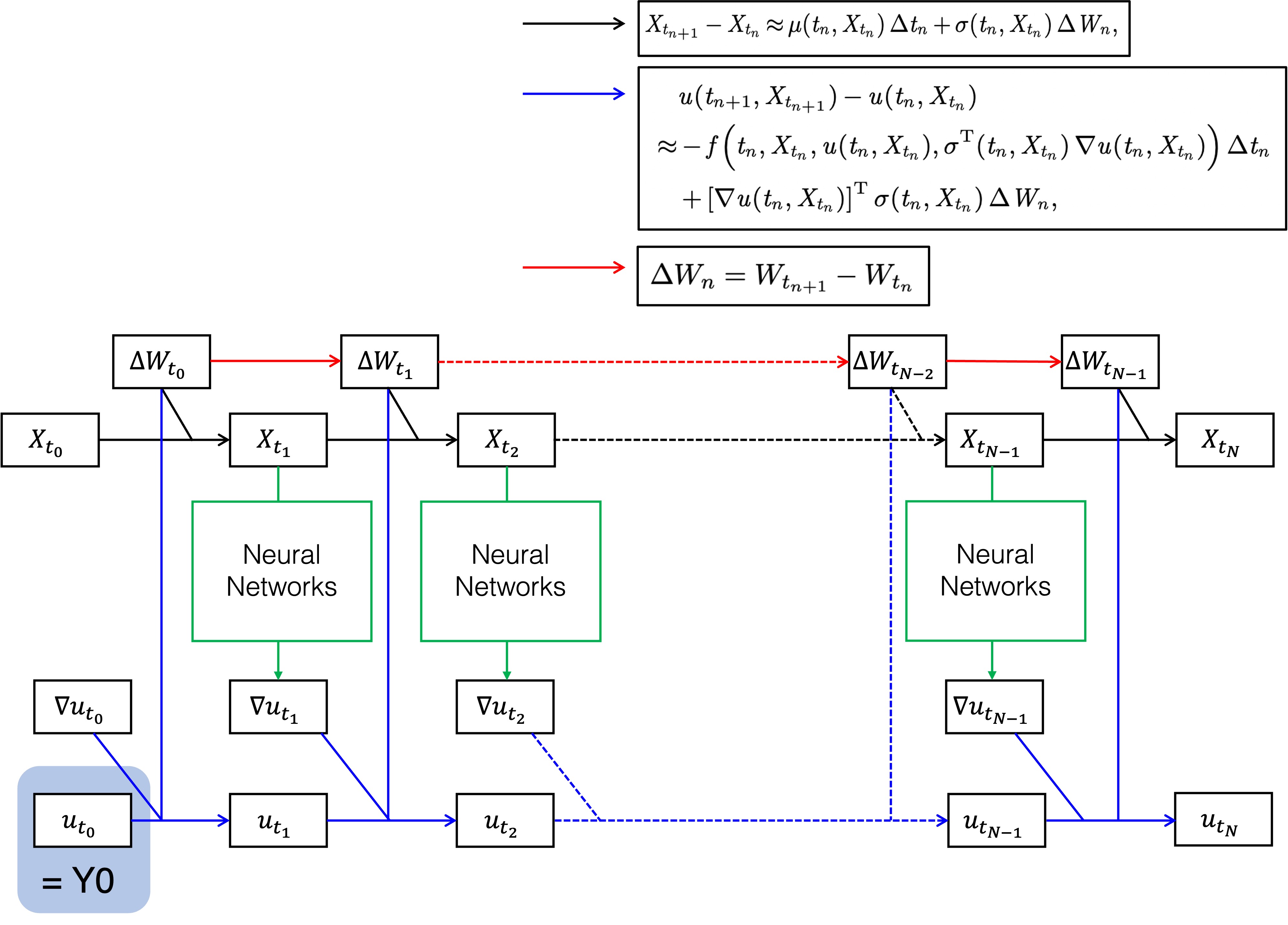
Unified evaluation of deep option pricing methods
By : Kentaro Minami
2022.10.03
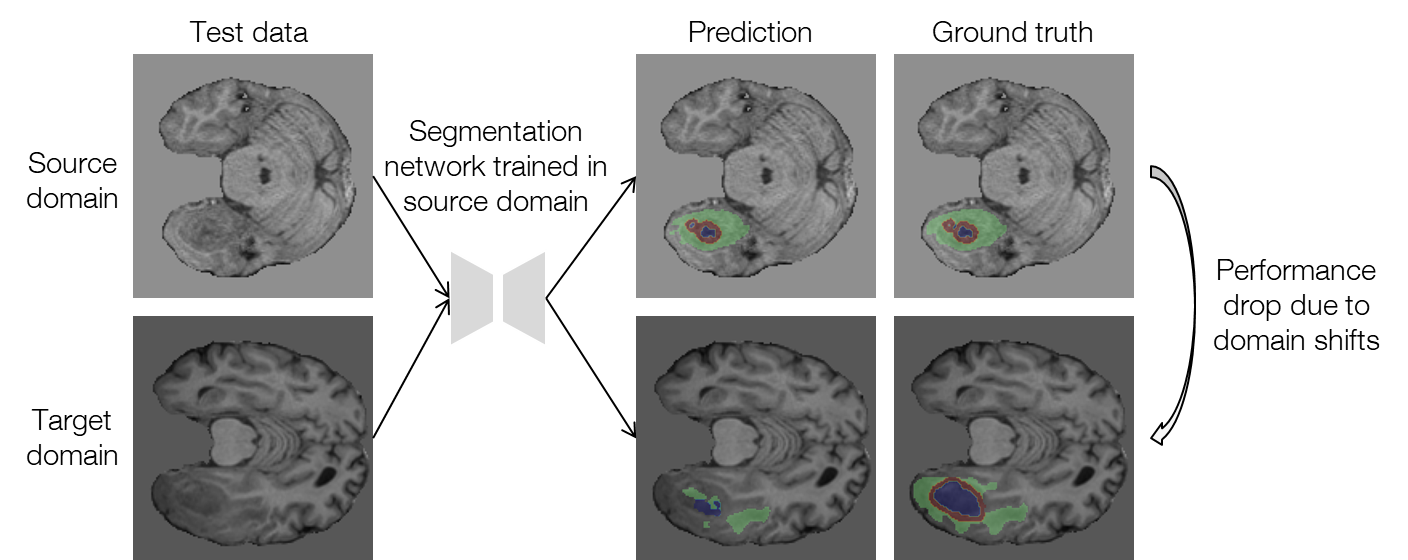
Test-time adaptation for brain tumor segmentation with cross-institutional MRI
By : Junichiro Iwasawa
2022.05.30
Development of Universal Neural Network for Materials Discovery
By : So Takamoto
2022.04.08
Neural network potential with charge transfer
By : Kosuke Nakago
2023.10.02
OpenTelemetry integration for Matlantis
By : Motoki Abe
2022.12.16
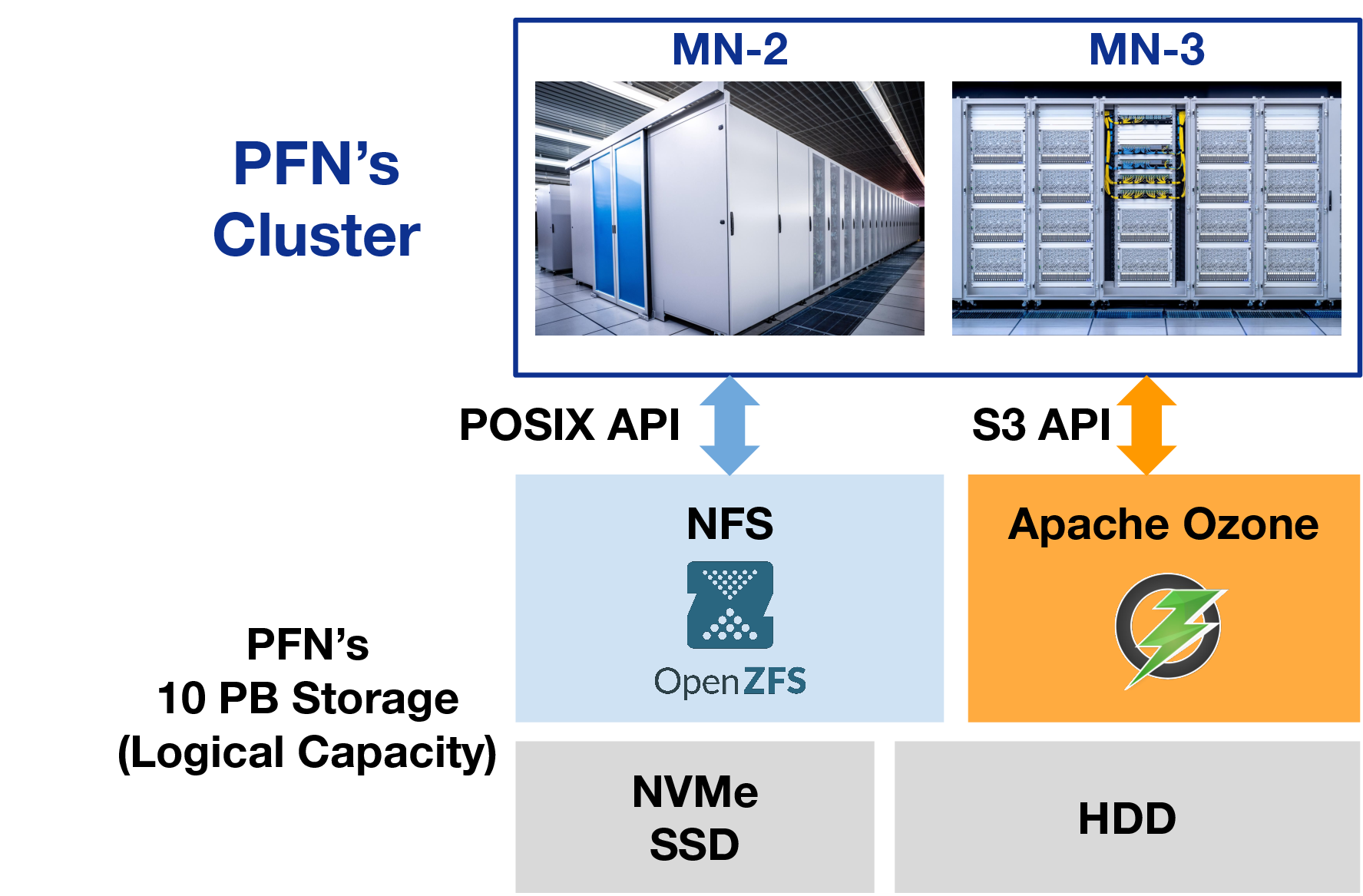
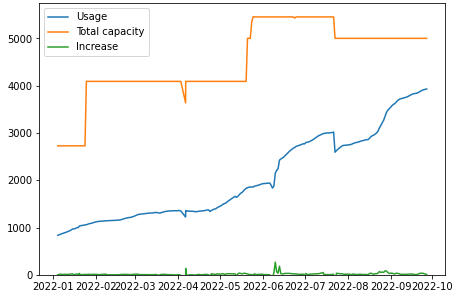
Two Years with Apache Ozone
By : Kohei Sugihara
2022.11.07
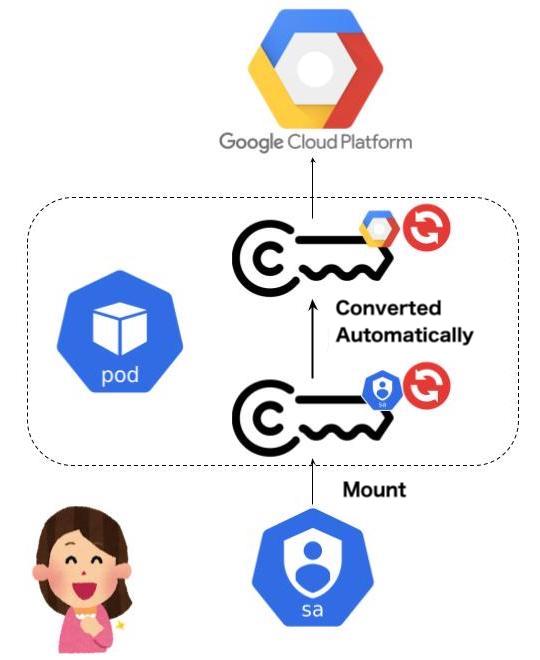
Webhook for Workload Identity Federation on Kubernetes clusters outside GCP is now available
By : Shingo Omura