Blog
Preferred Networks has released a beta version of an open-source, automatic hyperparameter optimization framework called Optuna. In this blog, we will introduce the motivation behind the development of Optuna as well as its features.
![]()
What is a hyperparameter?
A hyperparameter is a parameter to control how a machine learning algorithm behaves. In deep learning, the learning rate, batch size, and number of training iterations are hyperparameters. Hyperparameters also include the numbers of neural network layers and channels. They are not, however, just numerical values. Things like whether to use Momentum SGD or Adam in training are also regarded as hyperparameters.
It is almost impossible to make a machine learning algorithm do the job without tuning hyperparameters. The number of hyperparameters tends to be high, especially in deep learning, and it is believed that performance largely depends on how we tune them. Most researchers and engineers that use deep learning technology manually tune these hyperparameters and spend a significant amount of their time doing so.
What is Optuna?
Optuna is a software framework for automating the optimization process of these hyperparameters. It automatically searches for and finds optimal hyperparameter values by trial and error for excellent performance. Currently, the software can be used in Python.
Optuna uses a history record of trials to determine which hyperparameter values to try next. Using this data, it estimates a promising area and tries values in that area. Optuna then estimates an even more promising region based on the new result. It repeats this process using the history data of trials completed thus far. Specifically, it employs a Bayesian optimization algorithm called Tree-structured Parzen Estimator.
What is its relationship with Chainer?
Chainer is a deep learning framework and Optuna is an automatic hyperparameter optimization framework. To optimize hyperparameters for training a neural network using Chainer, the user needs to write a code for receiving hyperparameters from Optuna within the Chainer code. Given this code, Optuna repeatedly calls the user code, and the neural network is trained with different hyperparameter values until it finds good values.
Optuna is being used with Chainer in most of the use cases at PFN, but this does not mean Optuna and Chainer are closely connected with each other. Users can use Optuna with other machine learning software as well. We have prepared some sample codes that use scikit-learn, XGBoost, and LightGBM as well as Chainer. In fact, Optuna can cover a broad range of use cases beyond machine learning, like acceleration, providing an interface that receives hyperparameters and returns evaluation values, for instance.
Why did PFN develop Optuna?
Why did we develop Optuna even though there were already established automatic hyperparameter optimization frameworks like Hyperopt, Spearmint, and SMAC?
When we tried the existing alternatives, we found that they did not work or were unstable in some of our environments, and that the algorithms had lagged behind recent advances in hyperparameter optimization. We wanted a way to specify which hyperparameters should be tuned within the python code, instead of having to write separate code for the optimizer.
Key Features
Define-by-Run style API
Optuna provides a novel Define-by-Run style API that enables the user to optimize hyperparameters, even if the user code is complex, while maintaining higher modularity than other frameworks. It can also optimize hyperparameters in a complex space like no other framework could express before.
There are two paradigms in deep learning frameworks: Define-and-Run and Define-by-Run. In the early days, Caffe and other Define-and-Run frameworks were dominant players. Then, PFN-developed Chainer appeared as the first advocate of the Define-by-Run paradigm, followed by the release of PyTorch, and later, eager mode becoming the default in TensorFlow 2.0. Now the Define-by-Run paradigm is well recognized and appears to be gaining momentum to become the standard.
Is the Define-by-Run paradigm useful only in the domain of deep learning frameworks? We came to understand that we could apply a similar approach to automatic hyperparameter optimization frameworks as well. Under this approach, all existing automatic hyperparameter optimization frameworks are classified as Define-and-Run. Optuna, on the other hand, is based on the Define-by-Run concept and provides users with a new style of API that is very different from other frameworks. This has made it possible to give high modularity to a user program and access to complex hyperparameter spaces, among other things.

Pruning of trials using learning curves
When iterative algorithms like deep learning and gradient boosting are used, rough prediction on end results of training can be made from the learning curve. Using these predictions, Optuna can halt unpromising trials before the training is over. This is the pruning feature of Optuna.
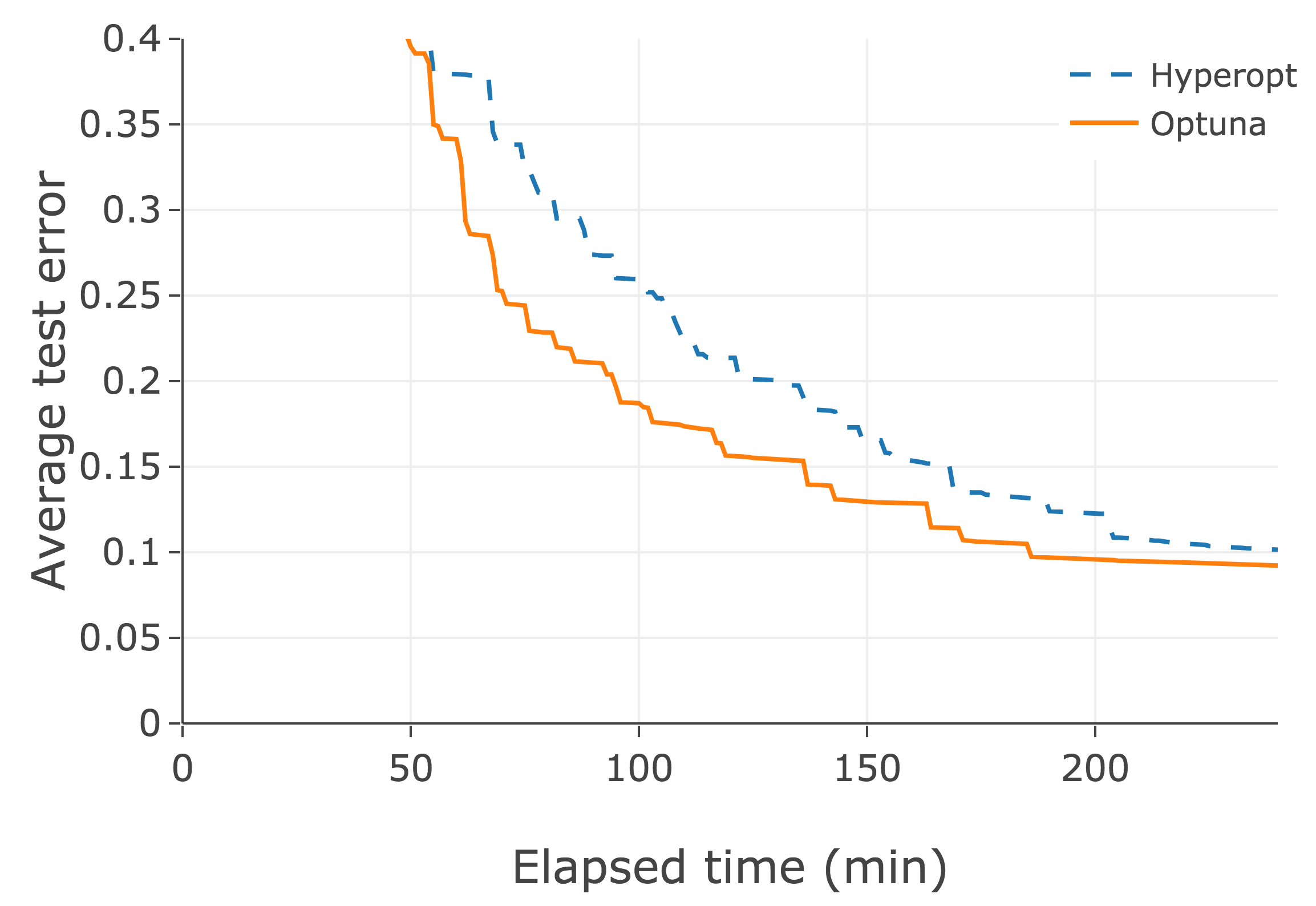
Existing frameworks such as Hyperopt, Spearmint, and SMAC do not have this functionality. Recent studies show that the pruning technique using learning curves is highly effective. The following graph indicates its effectiveness in performing a sample deep learning task. While the optimization engines of both Optuna and Hyperopt utilize the same TPE, thanks to pruning, the optimization performed by Optuna is more efficient.
Parallel distributed optimization
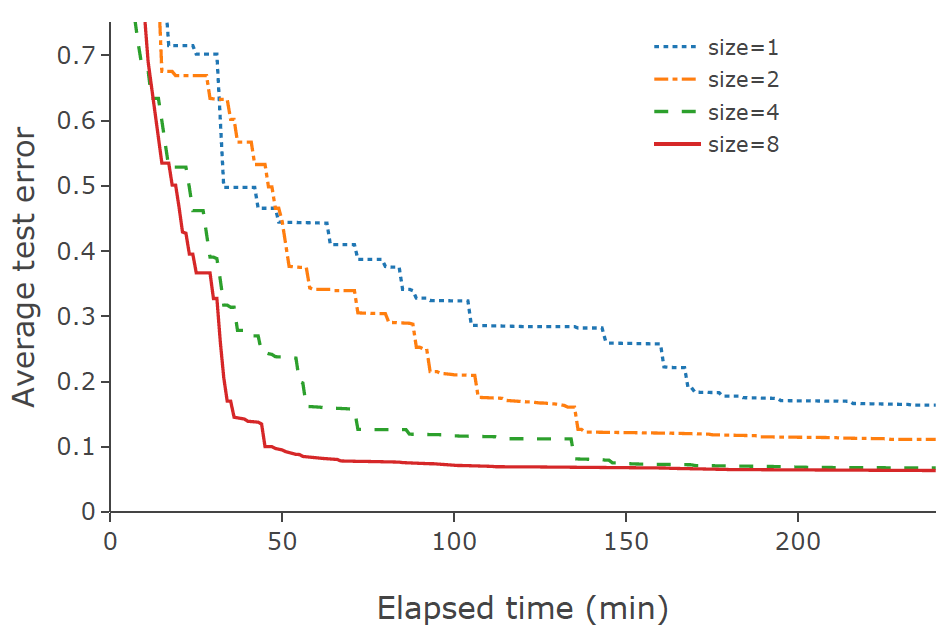
Deep learning is computationally intensive, and each training process is very time-consuming. Therefore, for automatic hyperparameter optimization in practical use cases, it is essential that the user can easily use parallel distributed optimization that is efficient and stable. Optuna supports asynchronous distributed optimization which simultaneously performs multiple trials using multiple nodes. Parallelization can make the optimization process even faster as shown in the following figure. In the below example, we changed the number of workers from 1, 2, 4, to 8, confirming that the parallelization has accelerated the optimization.
Optuna also has a functionality to work with ChainerMN, allowing the user to optimize training that requires distributed processing without difficulty. By making use of a combination of these functionalities, the user can execute objective functions that include distributed processing in a parallel, distributed manner.
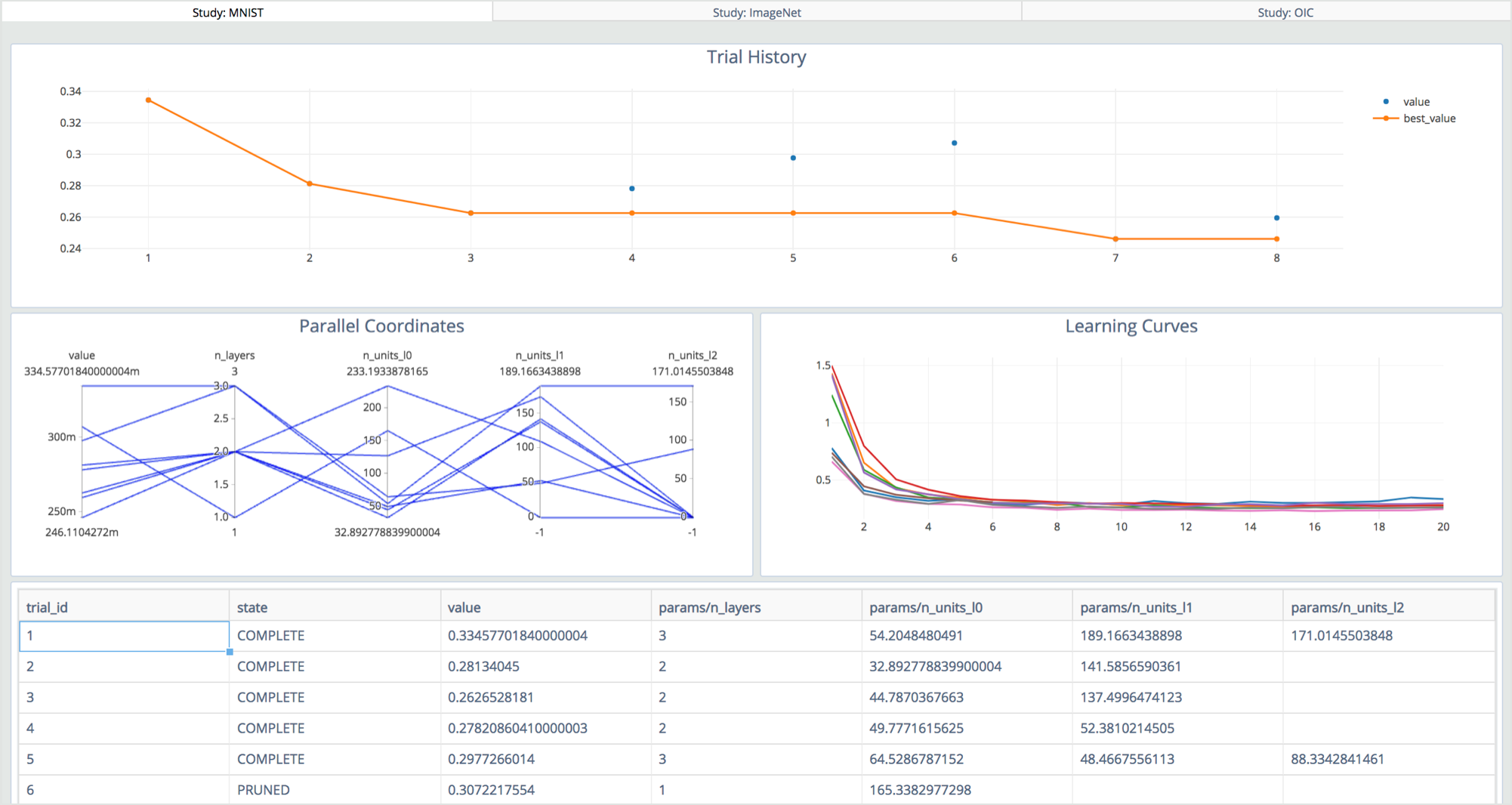
Visualized optimization on dashboard (under development)
Optuna has a dashboard that provides a visualized display of the optimization process. With this, the user can obtain useful information from experimental results. The dashboard can be accessed by connecting via a Web browser to an HTTP server which can be started by one command. Optuna also has a functionality to export optimization processes in a pandas dataframe, for systematic analysis.
Conclusions
Optuna is already in use by several projects at PFN. Among them is the project to compete in the Open Images Challenge 2018, in which we finished in second place. We will continue to aggressively develop Optuna to improve its integrity as well as prototyping and implementing advanced functionalities. We believe Optuna is ready for use, so we would love to receive your candid feedback.
Our objective is to speed up deep learning related R&D activities as much as possible. Our effort into automatic hyperparameter optimization is an important step toward this end. Additionally, we have begun working on other important technologies such as neural architecture search and automatic feature extraction. PFN is looking for potential full-time members and interns who are enthusiastic about working with us in these fields and activities.
Tag

