Blog
Preferred Networks, Inc. has completed ImageNet training in 15 minutes [1,2]. This is the fastest time to perform a 90-epoch ImageNet training ever achieved. Let me describe the MN-1 cluster used for this accomplishment.
Preferred Networks’ MN-1 cluster started operation this September [3]. It consists of 128 nodes with 8 NVIDIA P100 GPUs each, for 1024 GPUs in total. As each GPU unit has 4.7 TFLOPS in double precision floating point as its theoretical peak, the total theoretical peak capacity is more than 4.7 PFLOPS (including CPUs as well). The nodes are connected with two FDR Infiniband links (56Gbps x 2). PFN has exclusive use of the cluster, which is located in an NTT datacenter.

On the TOP500 list published in this November, the MN-1 cluster is listed as the 91st most powerful supercomputer, with approx. 1.39PFLOPS maximum performance on the LINPACK benchmark[4]. Compared to traditional supercomputers, MN-1’s computation efficiency (28%) is not high. One of the performance bottlenecks is the interconnect. Unlike typical supercomputers, MN-1 is connected as a thin tree (compared to a fat tree). A group of sixteen nodes is connected to a pair of redundant infiniband switches. In the cluster, we have eight groups, and links between groups are aggregated in a redundant pair of infiniband switches. Thus, if a process needs to communicate with different group, the link between groups becomes a bottleneck, which lowers the LINPACK benchmark score.

Distributed Learning in ChainerMN
However, as stated at the beginning of this article, MN-1 can perform ultra-fast Deep Learning (DL). This is because ChainerMN does not require bottleneck-free communication for DL training. While training, ChainerMN collects and re-distributes parameter updates between all nodes. In the 15-minute trial, we used the ring allreduce algorithm. With the ring allreduce algorithm, nodes communicate with their adjacent node in the ring topology. The accumulation is performed on the first round, and the accumulated parameter update is distributed on the second round. Since we can make a ring without hitting the bottleneck on full duplex network, MN-1 cluster can efficiently finish the ImageNet training in 15 minutes with 1024 GPUs.
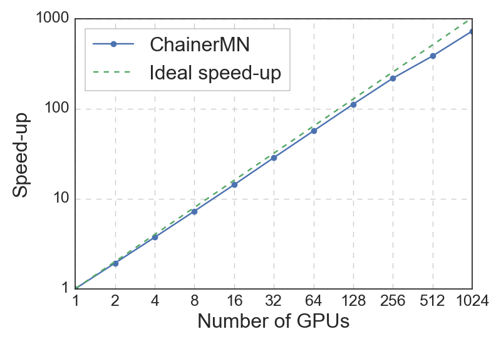
Scalability of ChainerMN up to 1024 GPUs
[1] https://arxiv.org/abs/1711.04325
[2] https://www.preferred-networks.jp/en/news/pr20171110
[3] https://www.preferred-networks.jp/en/news/pr20170920
[4] https://www.preferred-networks.jp/en/news/pr20171114

